【ComfyUI教程01】手把手安装ComfyUI + Z-Image-Turbo:程序员的第一课
基准版本:ComfyUI 0.18.1 + Z-Image-Turbo 本系列面向有编程基础的AI爱好者,从源码角度深度理解ComfyUI
📢 写在前面:本系列教程基于本地机器运行。目前暂不涉及任何在线服务提供商的推广——大家可以自行搜索了解。值得注意的是,16GB 以上显存的显卡及整机的费用并不便宜,更别说 RTX 5090、RTX PRO 6000 或 DGX Spark 等高端设备了,请大家理性消费。
硬件选择上,我们推荐 NVIDIA 显卡:CUDA 发展早,在 AI 软件底层已形成明显的时间壁垒。当然,macOS 和 AMD 平台同样可以使用 ComfyUI,效果可能略逊于 NVIDIA,但也是可行的方案。另外,笔记本显卡受限于功耗和硬件参数,实际表现与同型号台式机显卡差距较大,也请大家理性看待。
概述
前置知识:命令行基础、了解深度学习推理基本概念 学完本文你会:
- 在Windows上安装ComfyUI官方便携版
- 下载Z-Image-Turbo模型(nvfp4版本)
- 跑通第一个文生图工作流
- 理解NVIDIA 50系列显卡的FP4优势
磁盘空间需求:
- ComfyUI本体:约 2 GB
- Z-Image-Turbo模型(nvfp4):约 6 GB
- 其他缓存/输出:预留 10 GB+
- 总计建议:50 GB可用空间
首次生成时间:约40秒(取决于模型加载速度)

一、写作背景与创作计划
为什么要写这个系列?
市面上的ComfyUI教程,要么是给普通用户看的"一键启动器"式教程,要么是停在表面的功能罗列。作为程序员,我们受够了这种:
- ❌ 碰到问题靠"猜"
- ❌ 报错信息看天书
- ❌ 不知道背后发生了什么
- ❌ 用了一堆插件但不懂原理
- ❌ 只会点按钮,不会写代码
这个系列的目标:做最好的中文ComfyUI程序员教程,从源码角度理解ComfyUI。
创作计划(共65篇)
| 篇章 | 篇数 | 内容 |
|---|---|---|
| 入门篇 | 7 | 安装、配置、跑通第一个工作流 |
| 基础篇 | 10 | 节点系统、Prompt、采样器、显存管理 |
| 模型篇 | 8 | Flux、Z-Image、Wan2.2、LTX-Video、LoRA |
| 插件篇 | 9 | Manager、Impact Pack、ControlNet等 |
| 工作流篇 | 8 | 参数化、高清放大、局部重绘、调试 |
| LLM集成篇 | 6 | Ollama、LlamaCpp、Claude/GPT API |
| 音频/TTS篇 | 6 | F5-TTS、SadTalker、Wav2Lip |
| 高级篇 | 4 | 执行引擎、显存管理、模型加载 |
| 源码篇 | 3 | 手搓简易版ComfyUI |
| 插件开发篇 | 4 | 从零开发完整插件 |
程序员视角
不只讲怎么用,更讲为什么:
- 执行引擎怎么工作?
- 节点系统如何实现?
- 工作流JSON格式是什么?
- 如何写自定义节点?
不依赖启动器,直接用官方demo:
- 直接从GitHub下载官方包
- 不需要秋叶整合包
- 理解每一个依赖关系
二、环境准备:硬件和磁盘
2.1 硬件要求
| 配置 | 要求 |
|---|---|
| 显卡 | NVIDIA RTX 5070 Ti(Blackwell架构) |
| 内存 | 32GB+ |
| 显存 | 16GB+ |
RTX 50系列特性:RTX 5070 Ti(Blackwell架构)支持FP4精度,这也是本系列选择nvfp4版本的主要原因。
2.2 磁盘空间
📦 磁盘空间预估
├── ComfyUI本体(含Python环境) ~2 GB
├── Z-Image-Turbo模型(nvfp4) ~6 GB
│ ├── diffusion_model ~3.5 GB
│ ├── text_encoder ~1.8 GB
│ └── vae ~0.6 GB
├── 临时缓存/输出 ~5 GB
└── 预留空间 ~10 GB
─────────────────────────────────
总计 ~25 GB(建议50GB)本教程实测环境:
显卡: NVIDIA GeForce RTX 5070 Ti (16GB显存)
内存: 32GB
PyTorch: 2.9.1+cu130
Python: 3.13.11
ComfyUI: 0.18.1
comfy-aimdo: 0.2.12如果你只用Z-Image-Turbo:25GB足够 如果要尝试多个模型:建议预留50GB以上
三、安装ComfyUI(官方便携版)
我们不用秋叶启动器,不用任何第三方整合包。直接用官方原版。
3.1 下载ComfyUI
访问GitHub releases页面:
https://github.com/comfyanonymous/ComfyUI/releases下载最新的便携版(Windows):
- 文件名类似
ComfyUI_windows_portable.7z - RTX 5070 Ti用户,下载CUDA 13.0版本
为什么用官方便携版?
- 环境隔离,不影响系统Python
- 干净,没有第三方修改
- 便于学习原理
3.2 解压
# 7z解压(Windows可用7-Zip)
7z x ComfyUI_windows_portable_cu130.7z.001 -oD:\AI\ComfyUI解压后目录结构:
ComfyUI/
├── ComfyUI/ # 核心代码
│ ├── main.py # 启动入口
│ ├── models/ # 模型目录
│ ├── custom_nodes/ # 插件目录
│ └── ...
├── python_embeded/ # 内置Python环境
├── update/ # 更新脚本
└── run_nvidia_gpu.bat # ⭐ NVIDIA显卡启动脚本3.3 启动ComfyUI
# 双击运行,或命令行执行
.\run_nvidia_gpu.bat启动成功后会看到:
[Server started] http://127.0.0.1:8188打开浏览器访问 http://127.0.0.1:8188,看到界面说明安装成功。
⚠️ 首次启动可能较慢,因为需要初始化Python环境和下载一些依赖。
四、Z-Image-Turbo:为什么选它?
⚠️心急的同学可以先跳到后面看生成效果
4.1 Z-Image-Turbo是什么?
阿里通义实验室开源的高效文生图模型,特点:
| 特性 | 说明 |
|---|---|
| 参数量 | 6B(60亿) |
| 架构 | S3-DiT(Scalable Single-Stream DiT) |
| 推理步数 | 仅需8步(传统SD需要20-50步) |
| 中文支持 | 优秀 |
| 显存要求 | 8GB可跑(nvfp4版本) |
4.2 nvfp4 vs bf16:50系列用户的正确选择
这是给NVIDIA 50系列(Blackwell架构)用户的重要提示。
什么是FP4?
FP4是一种4位浮点量化,类似于文件压缩。相比bf16:
- 显存占用不到一半
- 50系列Tensor Core的FP4性能是上代2倍以上
对比
| 精度 | RTX 5070 Ti | 显存占用 |
|---|---|---|
| bf16 | ✅ 可用 | 12GB+ |
| fp8 | ✅ 可用 | ~8GB |
| fp4 | ✅ 原生支持 | ~6GB |
为什么nvfp4更好?
- 显存友好:12GB显存就能跑,而bf16需要更多
- 速度快:Blackwell的第五代Tensor Core对FP4有专门优化
- 质量损失小:肉眼几乎无法区分
重要:nvfp4版本需要Blackwell架构的RTX 5070 Ti支持。
4.3 下载Z-Image-Turbo模型
模型下载地址(国内可访问):
# HuggingFace 镜像站
https://hf-mirror.com/Comfy-Org/z_image_turbo/tree/main/split_files页面中包含以下文件,按需下载:
| 文件 | 说明 | 大小 |
|---|---|---|
diffusion_model/ | 主扩散模型,核心去噪网络 | ~3.5GB |
text_encoder/ | 文本编码器,将Prompt转为向量 | ~1.8GB |
ae.safetensors | VAE,负责图像编解码 | ~0.6GB |
放入ComfyUI模型目录:
ComfyUI/
└── models/
└── Z-Image-Turbo-nvfp4/ # 新建此目录,放入下载的模型
├── diffusion_model/ # 主模型文件夹
├── text_encoder/ # 文本编码器
└── ae.safetensors # VAE4.4 快速理解:扩散模型的四大组件
作为程序员,你应该知道这些组件背后的原理:
Diffusion Model(扩散模型)
输入:噪声 + 文本条件
↓
逐步去噪(8步/20步/50步)
↓
输出:清晰图像本质:一个U-Net结构的神经网络,学习如何从噪声中恢复出图像。
Text Encoder(文本编码器)
本质:一个Transformer模型,将人类语言转换为模型能理解的向量表示。
- 早期SD用CLIP(OpenAI)
- Z-Image-Turbo使用Qwen作为文本编码器
- 决定模型对语义的理解能力
VAE(变分自编码器)
本质:图像的"压缩器"和"解压器"
原始图像 (512x512x3) → 编码器 → 潜空间 (64x64x4) → 解码器 → 原始图像
压缩率:8x8=64倍- 编码器:将图像压缩到低维潜空间
- 解码器:将潜空间表示还原为图像
- 节省计算量的关键
LoRA(低秩适配)
本质:一种微调技术,通过低秩矩阵近似来"轻量修改"大模型。
原权重 W + ΔW = 新权重
ΔW = A × B(两个小矩阵)- 训练成本低(只需训练LoRA,不改原模型)
- 文件小(通常50MB-200MB)
- 可叠加多个LoRA
五、扩散模型 vs 语言大模型:本质区别
作为程序员,你可能更熟悉GPT、Claude这类大语言模型(LLM)。Z-Image-Turbo是扩散模型,两者有本质区别:
| 维度 | 大语言模型 (LLM) | 扩散模型 (Diffusion) |
|---|---|---|
| 输入 | 文字 → 文字 | 文字 → 图像 |
| 输出 | Token序列 | 像素矩阵 |
| 核心网络 | Transformer (Decoder) | U-Net + Transformer |
| 处理方式 | 自回归生成(一个字一个字吐) | 渐进式去噪(一次性生成) |
| 类比 | 写文章 | 画画 |
5.1 工作方式对比
LLM的工作方式(自回归)
输入: "今天天气"
↓
GPT: 预测下一个词 "很"
GPT: 预测下一个词 "好"
GPT: 预测下一个词 "。"
...一个字一个字往外吐扩散模型的工作方式(一步到位)
输入: 噪声 + "晴天"
↓
[去噪 step 1] → [去噪 step 2] → ... → [去噪 step 8]
↓
一次性输出完整图像5.2 为什么Z-Image-Turbo只用8步?
传统SD需要20-50步,因为它是"盲猜"——每步都要从随机噪声中猜一个像素。
Z-Image-Turbo的Turbo模式用了蒸馏技术,让模型"学会"一步走更大的步幅,本质上是用训练换推理速度。
传统SD: 步数=50, 每步猜1像素 → 慢但稳
Turbo: 步数=8, 每步猜8像素 → 快且准(因为训练得好)5.3 两者的技术栈差异
| 组件 | LLM | 扩散模型 |
|---|---|---|
| 文本编码 | Tokenizer + Embedding | CLIP/Qwen Text Encoder |
| 核心网络 | Transformer Block | U-Net Block |
| 输出层 | Linear (vocab_size) | VAE Decode |
| 生成控制 | Temperature, Top-p | CFG, Steps |
5.4 ComfyUI连接两者的方式
ComfyUI的强大之处在于:你可以用LLM生成Prompt,扩散模型生成图像。
LLM (Claude/GPT) → 生成Prompt → ComfyUI → 扩散模型 → 图像这就是为什么我们后续会有LLM集成篇章。
六、加载官方工作流模板
6.1 从官方文档加载
ComfyUI支持直接导入官方工作流JSON。
- 打开
http://127.0.0.1:8188 - 点击右下角 "Load" 按钮
- 官方Z-Image-Turbo工作流地址:
https://docs.comfy.org/zh-CN/workflows/z-image-turbo在网页上找到 "Download" 或 "Copy" 按钮,粘贴到ComfyUI。或者直接用左下角模板界面直接加载 
6.2 工作流结构
官方模板提供两个视图:
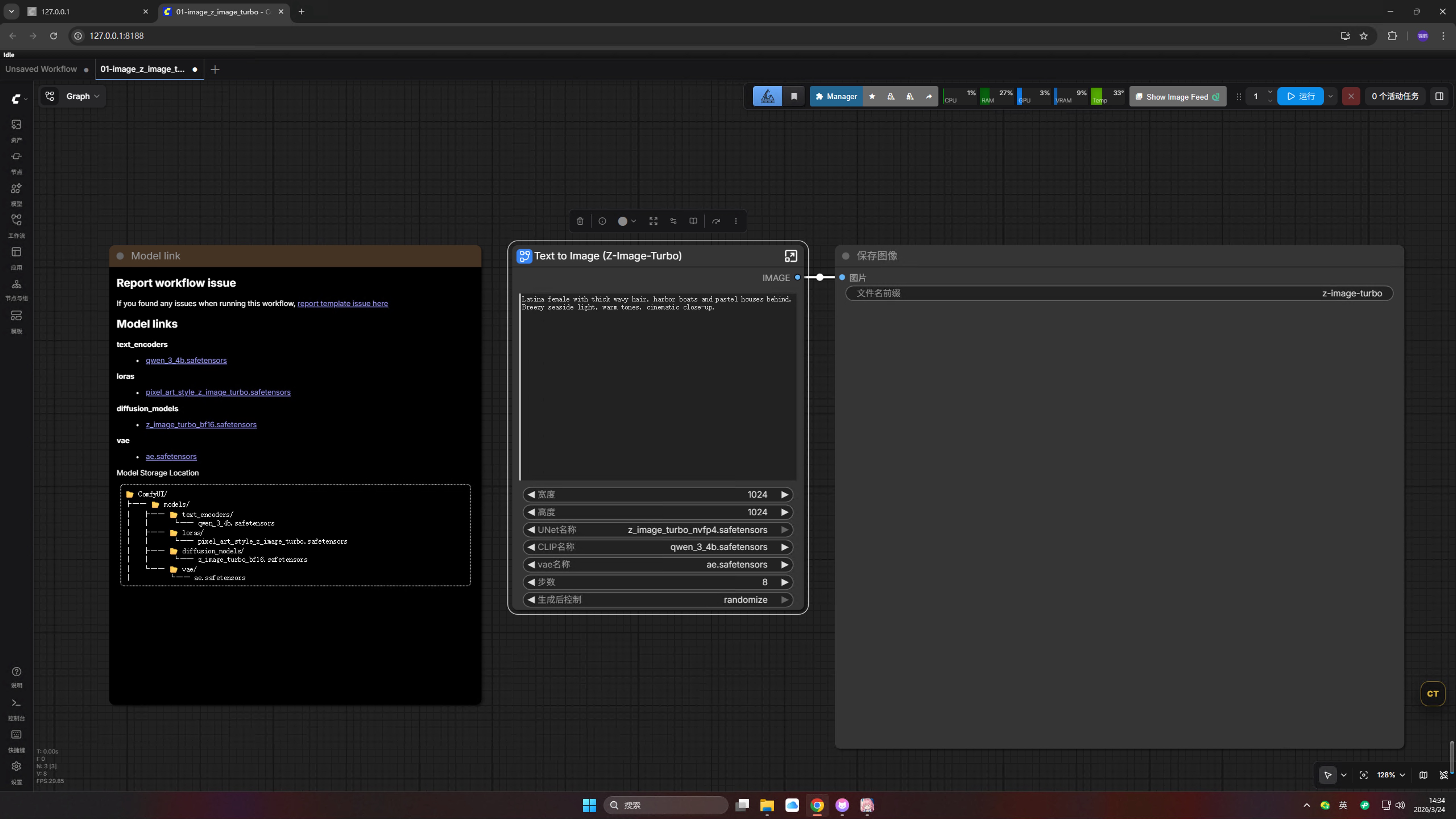
6.2.1 整合视图(新手用这个)
右上角有一个"Colla"按钮,点击可以展开/收起详细节点。
整合视图把多个节点打包成一个:
- 只需选择模型
- 只需输入提示词
- 点击生成即可
6.2.2 展开视图(新手也该了解)
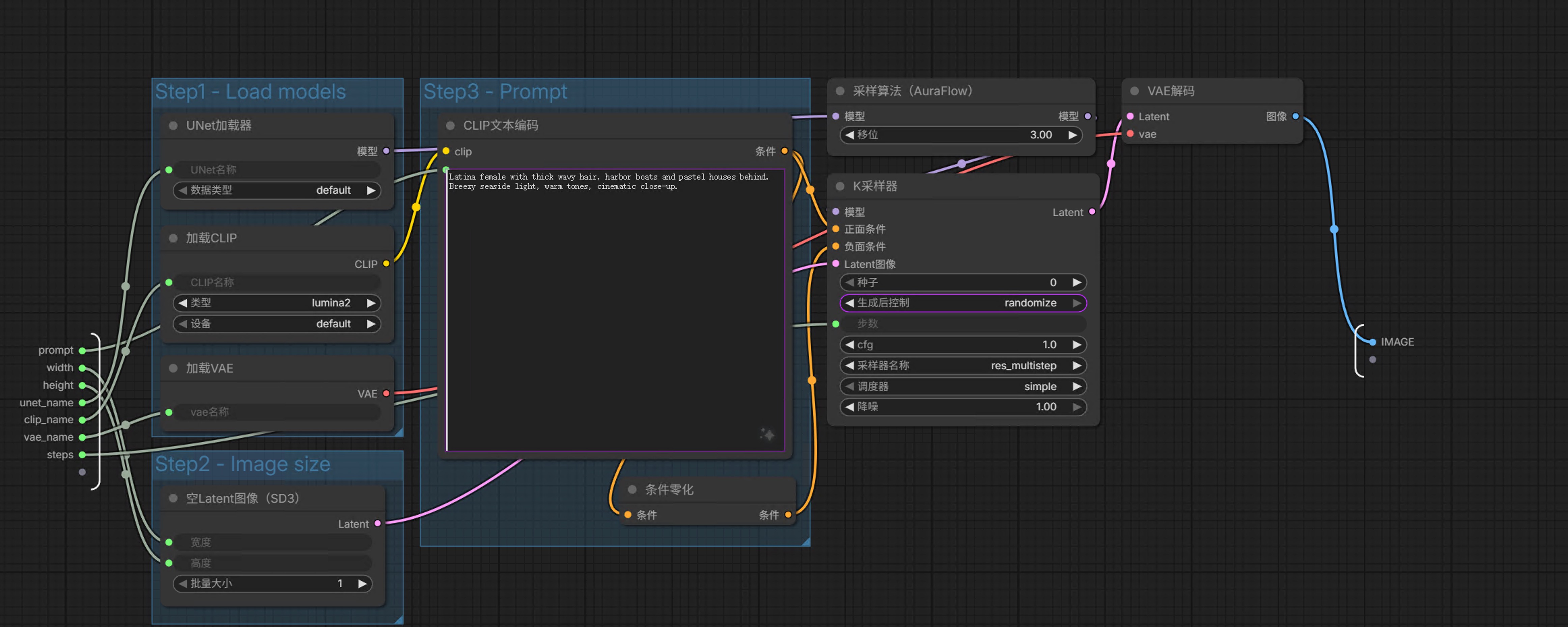
点击右上角展开后,你会看到完整的工作流:
┌─────────────────────────────────────────────────────────────────┐
│ Z-Image-Turbo 完整工作流 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────┐ │
│ │ LoadModel │ 加载Z-Image-Turbo模型 │
│ │ (Z-Image-Turbo) │ 输出: model, clip, vae │
│ └───────┬──────────┘ │
│ │ │
│ ┌─────┼─────┬────────────────────┐ │
│ ▼ ▼ ▼ ▼ │
│ ┌────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ │ │ CLIPTextEncode│ │EmptyLatent │ │
│ │ │ │ │ │Image │ │
│ │ │ │ 正面提示词 │ │width:512 │ │
│ │ │ └──────┬───────┘ │height:512 │ │
│ │ │ │ │batch_size:1│ │
│ │ MODEL │COND └──────┬───────┘ │
│ └────┼────────┘ │ │
│ │ ┌─────────────────────┘ │
│ │ │ │
│ │ ▼ │
│ │ ┌──────────────────────┐ │
│ │ │ Z-Image-Turbo │ │
│ │ │ KSampler │ │
│ │ │ steps: 8 │ ← 核心去噪过程 │
│ │ │ cfg: 1.5 │ │
│ │ │ sampler: euler │ │
│ │ └──────────┬──────────┘ │
│ │ │ latent │
│ │ ▼ │
│ │ ┌──────────────────────┐ │
│ │ │ VAEDecode │ 潜空间 → 像素空间 │
│ │ └──────────┬───────────┘ │
│ │ │ image │
│ │ ▼ │
│ │ ┌──────────────────────┐ │
│ │ │ SaveImage │ 保存到output目录 │
│ │ └──────────────────────┘ │
│ │ │
│ └───────────────────────────────────── clip ─────────────┘
│ │
└─────────────────────────────────────────────────────────────────┘6.3 关键节点详解
| 节点 | 作用 | 重要参数 |
|---|---|---|
| LoadModel | 加载整个Z-Image-Turbo模型 | 选择模型文件 |
| CLIPTextEncode | 把文字转成AI能懂的"向量" | 正面提示词 |
| EmptyLatentImage | 创建一个"空白画布" | width/height: 尺寸 batch_size: 一次生成几张 |
| KSampler | 核心!去噪过程在这里发生 | steps: 推理步数 cfg: 引导强度 seed: 随机种子 sampler: 采样算法 |
| VAEDecode | 把潜空间转成真实图片 | - |
| SaveImage | 保存到output目录 | - |
6.4 重要参数详解
steps(步数)
步数越多 → 质量越好 → 速度越慢- Z-Image-Turbo Turbo模式:4-8步
- 传统SD模型:20-50步
- 步数超过8对Turbo模型没有额外帮助
cfg(引导强度)
cfg = 1.0: 严格按提示词生成
cfg = 7-8: 常见SD模型的默认值- Z-Image-Turbo建议:1.0-2.0
- cfg太高会导致颜色过饱和、细节丢失
seed(种子)
- 相同的seed + 相同的提示词 = 相同的结果
- 想要可复现的结果?记下seed
width / height
- 512x512:标准尺寸,速度快
- 1024x1024:高清,推荐
- 可以是非正方形,如 1024x768
七、生成你的第一张图
7.1 界面说明
官方模板右上角有折叠/展开按钮:
- 整合视图(折叠):快速操作,只填提示词和点击生成
- 展开视图:展示完整工作流节点,可深入学习
建议:先用整合视图快速出图,再展开理解节点结构。
7.2 提示词
正面提示词(英文效果更好):
A beautiful sunset over the ocean, golden hour lighting, dramatic clouds, hyperrealistic, 8k中文也可以:
一张赛博朋克风格的城市夜景,霓虹灯光,下雨的街道,科幻感简化处理:为降低入门门槛,这里先不填负面提示词,后续会单独讲解。
7.3 点击生成
- 点击右下角 "Queue Prompt"
- 等待生成(约40秒,视模型大小和显存情况)
- 查看结果
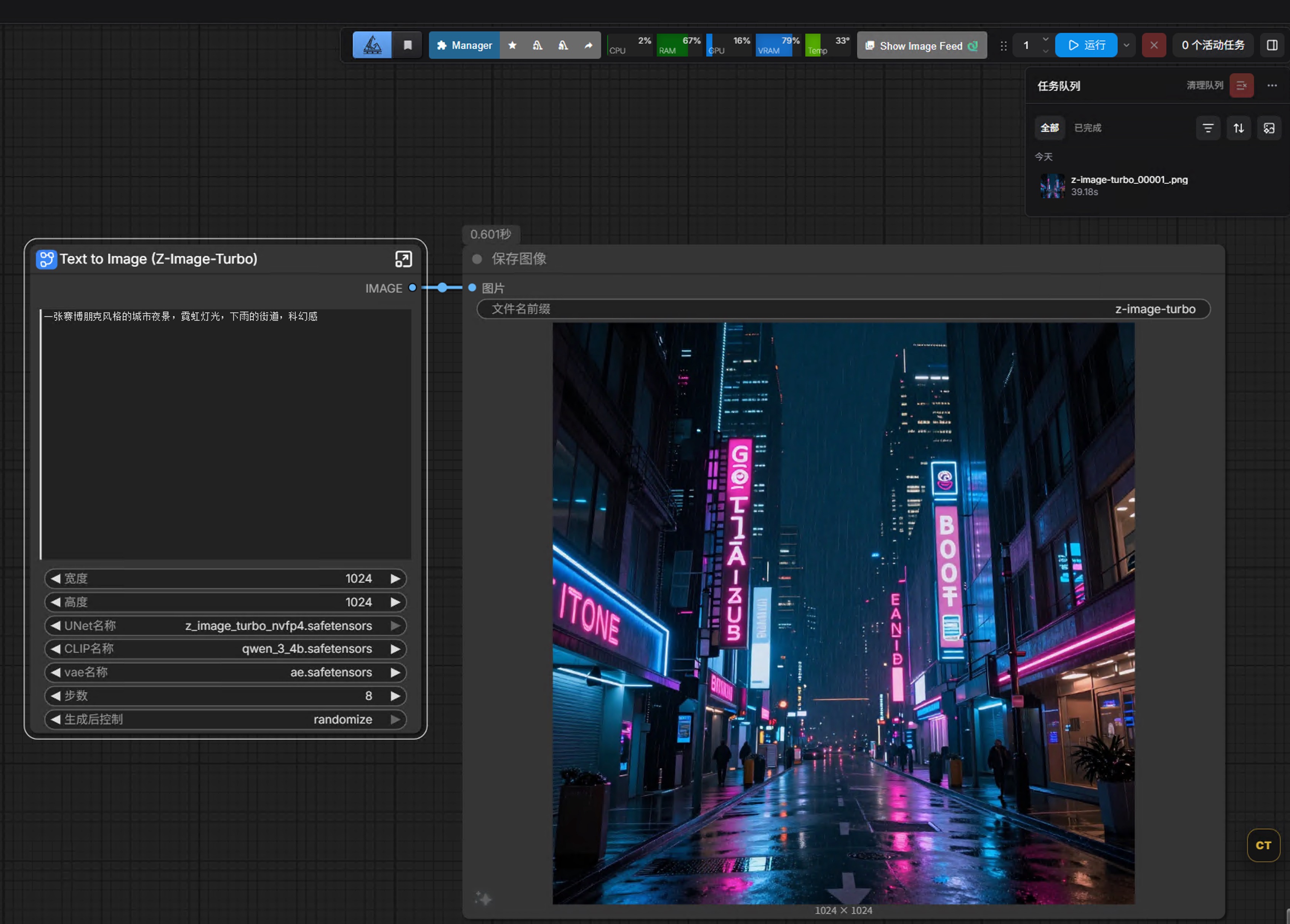
7.4 常见问题
Q: 模型加载报错?
检查模型文件是否完整放入
models/Z-Image-Turbo-nvfp4/目录
Q: CUDA out of memory?
确保使用nvfp4版本,bf16版本需要更多显存
Q: 生成的黑图?
检查steps是否设置为4-8,Turbo模型步数过多反而效果差
八、这一讲我们学到了什么?
- ComfyUI便携版安装:不依赖任何第三方启动器
- NVIDIA RTX 5070 Ti特性:Blackwell架构支持FP4精度
- Z-Image-Turbo:阿里开源的高效模型,8步出图
- nvfp4:RTX 5070 Ti用户应选择nvfp4,显存占用减半
- 扩散模型四大组件:Diffusion Model、Text Encoder、VAE、LoRA
- 扩散模型 vs LLM:前者是"一步到位"生成图像,后者是"逐字生成"文本
下一步
下一讲我们将:
- 深入理解ComfyUI的节点系统
- 手动搭建一个文生图工作流
- 解析工作流JSON格式
预告:你将理解LoadCheckpoint、KSampler、VAEDecode这些节点背后的数据流,理解ComfyUI执行引擎的原理。
附录:RTX 5070 Ti用户须知
| 问题 | 解答 |
|---|---|
| Q: RTX 5070 Ti支持FP4吗? | 支持,Blackwell架构原生支持 |
| Q: 必须用nvfp4吗? | 不是,但nvfp4更省显存 |
| Q: bf16能用吗? | 能,但需要更多显存 |
| Q: 其他模型也支持FP4吗? | 越来越多,Flux等已支持 |